


Why “delve” is an obvious sign of AI writing
AI text generators tend to overuse the word “delve”. Now we know why.

If AI writing sounds a bit like a 90's email scam to you, there’s a surprisingly human reason behind it. Last year I published a very popular guide (if I do say so myself — it’s had 58K views) on how readers can spot the telltale signs and linguistic patterns of AI text. By far the top culprit was the word “Delve”.
“Delve into the realms of artificial intelligence tools and discover how they can unlock your creativity, improve efficiency, and transform content creation.”
🤖 🤮
Horrible, right?
In fact, a recent study by Jeremy Nguyen PhD found the frequency of the word “delve” in PubMed articles since the end of 2022 has increased by approximately 400 percent — which coincides with the rise of ChatGPT.

The “Delve” Dilemma in AI-Generated Text
I’ve worked as a copywriter, editor, proofreader, and an academic grading hundreds of papers a semester, and I’d neverseen the word “delve” appear as much as it does now in anodyne, artificially generated content. But here’s the conundrum: if AI text is generated based on human writing, where on earth is it getting such a preponderance of the word “delve”?
Is it emergent behavior? Or perhaps an intentional watermark inserted by developers so that AI content isn’t re-ingested as training data in the future?

Well, it turns out, “Where on earth?” is exactly the right question. But first, let’s del… er, dig a little deeper into how Large-scale language Models are developed and trained, and why it’s necessary to refine models through techniques like Reinforcement Learning from Human Feedback (RLHF).
Patterns vs. Comprehension
LLMs have been trained on vast corpora of texts: hundreds of gigabytes of data from books, websites, scientific papers, Wikipedia, news articles, and social media. It would take one human 380 years of continuous reading — without breaks — to read the equivalent amount of text that an AI model has been trained on. Patterns in this vast amount of information enable AI to generate text and answer queries, but it doesn’t understand a word of it.
The Alien Chef Analogy
AI has no real comprehension nor knowledge of the information it serves us with. Kem-Laurin Lubin, Ph.D-C gives a great metaphor to explain this:
“Imagine you’re abducted by aliens and brought to a planet resembling Earth. You’re assigned the role of a chef for a vital event, using unfamiliar ingredients from an alien garden, plus what appear to be spices from their kitchen. Suppose you’ve never cooked before and now face a dire consequence for any mistake. Consider AI as a chef using data as ingredients.

This estrangement, this ‘alienness’, is important to keep in mind when discussing Artificial Intelligence. We should be careful not to personify neural networks, nor to use our human ontologies to explain them away.
I’ve written before on the similarities and vast differences between how AI and humans perceive the world (even the word ‘perceive’ is a fallacy), with fundamental differences in metameres (the variables we ‘know’ about the world instinctively from lived experience, whereas AI uses a cluster of data points that are incomprehensible to humans). We’re each blind to how the other interprets information and the universe as if we are existing — or perhaps I should better say ‘operating’ — in parallel, yet divergent, realities.
Related article: How AI Perceives the World: Not Quite Seeing Things Eye-to-Eye
Why humans and AI perceive visual information differently medium.com
The Ticking Clock Conundrum
For instance, a human knows that the hands of a clock move steadily. We impose a measure of time on this fact. We have chronoception, a sense of the ebbs and flows of the subjective experience of time — that allows us to link duration with our perception and temporal frames of reference in our language and cognition. Put simply; we know a clock ticks, and we ‘feel’ that ticking echoed in our own pulse and awareness of the unfolding of events.
AI image generators, on the other hand, tend to display the time as 10:10 because AI has no real world experiential knowledge. The training data it has ingested of clocks disproportionately represents the time as 10:10 (due to an abundance of advertising images that tend to show watches at 10:10).
Even though both humans and AI have been exposed to the same images, when humans buy a watch from an inflight magazine, we’re not confused by the fact that the watch shows the real-time, and not the time advertised.
AI can’t make the leap between the cliches of clocks in visual culture and the reality that they are not all set to 10:10 — or rather, it makes the more logical conclusion — that cultural representations are, well, representative (which has huge implications for racial biases, but that’s another article!)
Cooking the Books: A Recipe for Disaster?
But what does this have to do with “delve”, at the end of the day? Well, to continue Lubin’s analogy, AI is a bewildered cook in an alien kitchen; the meals it makes are derived from a vast cookbook it can’t comprehend. It’s an algorithmic “stranger in a strange land” who can’t taste-test the cuisine.
“Mixing data without understanding can lead to harmful outcomes, much like mistaking a toxic “alien” plant that looks like a carrot but not a carrot.”
Kem-Laurin Lubin, Ph.D-C
I think Lubin’s thought experiment is masterful, along the lines of the Turing Test. AI has a cookbook, and all the right ingredients, but when we request generative content we’re asking it to whip up new meals. It has no idea if they’re edible. It reminds me of Rachel’s attempt to make an English trifle dessert in the TV show Friends, where she runs the stuck-together pages of a cookbook together and accidentally makes a “beef custard”:
Refining AI’s Palate: Human Feedback and RLHF
Accordingly, we have to assign a test taster to train the AI. There are two main ways this is done: using a GAN (Generative Adversarial Network) or RLHF (Reinforcement Learning from Human Feedback). A GAN is when two networks are trained against each other, competing for rewards, to generate more authentic output. To continue the analogy: our AI chefs engage in a bake-off, and compare each other's results against their cookbooks to say “Yes, this does indeed appear to resemble a cake”.
This is ultimately where we are going with OpenAI’s Q*, in which the reinforcement is so complex and sophisticated that an AGI would be capable of self-improvement (a concept known as ‘Superalignment’).
However, humans haven’t been left in the dust yet. Although AI systems are getting increasingly sophisticated, we still remain essential to the process. We’re the tasters, the judges, certifying that what the AI produces is not just technically correct but palatable and appropriate for human consumption.
Learning From Us: The Human Element in Language Reinforcement
Reinforcement Learning from Human Feedback uses human preferences to guide the LLM to refine its output. It helps AI to align more to our tastes, and less with its own algorithmic tendencies. In RLHF, human reviewers rate the outputs of the AI based on various criteria, such as relevance, coherence, and engagement, and dispense the rewards accordingly.
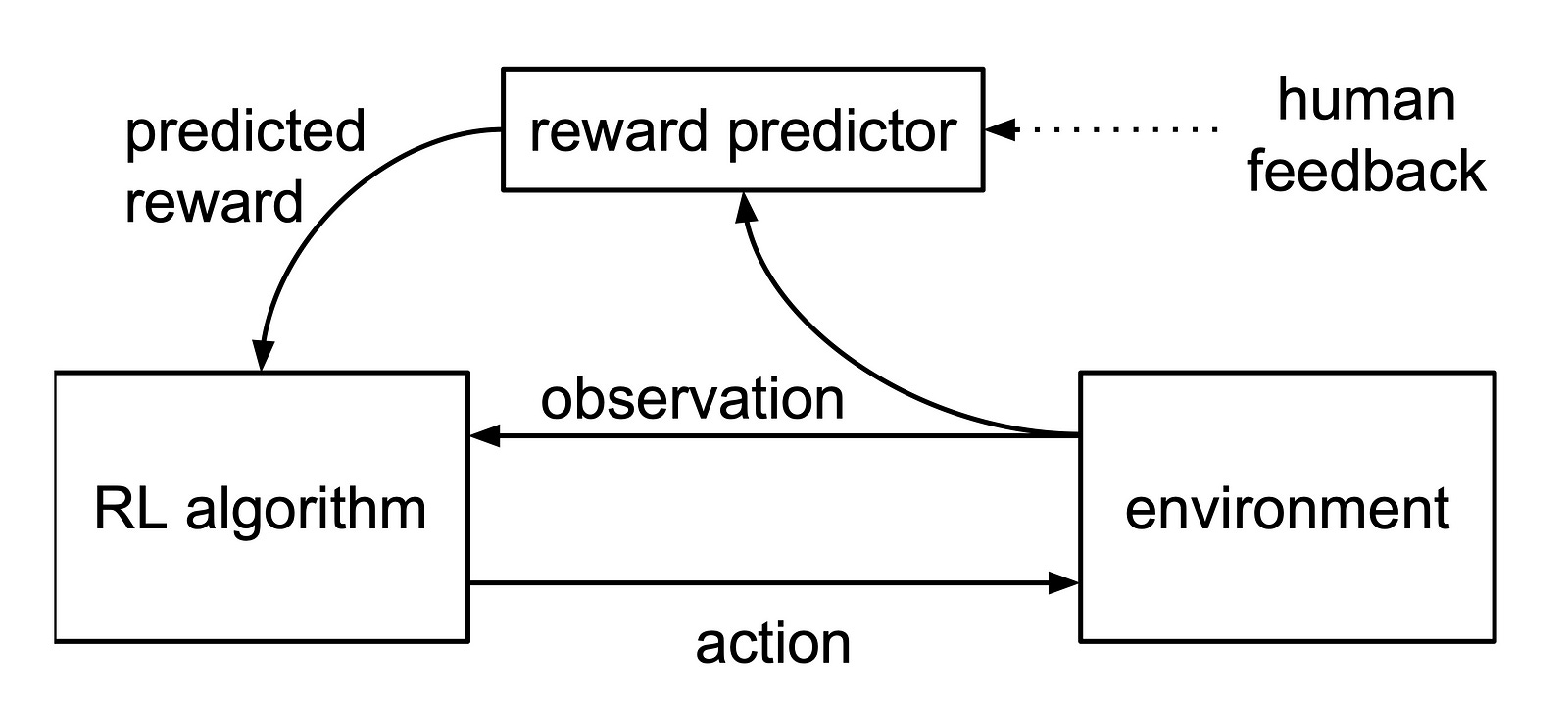
However, models honed through RLHF techniques might exhibit a skewed preference for certain terms, such as “delve”, especially if these reviewers favor more formal or evocative language. Alex Hern, tech writer over at The Guardian, suggests this could explain the paradoxical preponderance of the word “delve” when it is not equally overrepresented in training sets.
The "Delve" Phenomenon Explained
According to Hern’s theory, it’s due to human influence that “delve” is peppered throughout AI outputs. When feedback loops are fine-tuned based on repeated responses from a limited sample of users who favor particular phrases or stylistic quirks, the AI learns that these are desired expressions to replicate in text generation.
This reinforcement amplifies certain words or phrases that humans find appealing. So next time you start to blame AI for “delving” too deep, look no further than our fellow humans. It reminds me of that anti-drug PSA campaign from the 1980s:

Yet this leads us to another question: why would “delve” be a human feedback mistake if many readers recognize it as sounding spammy?
Cultural Influences on AI-Language Style Preferences
Hern suggests that it’s a result of the AI monopolies outsourcing cheap RLHF tasks to the global South, hiring cut-price workers in Nigeria and Kenya to monitor and adjust linguistic preferences.
These nations — with their complex historical interactions with the English language due to colonial legacies — may overrepresent formal or literary terms like ‘delve’ within their feedback, which the AI systems then adopt disproportionately.
Stephanie Busari, Senior Editor for Africa at CNN, tweeted, “People who learn English as a second language tend to speak it more formally and not colloquially like in the UK or US.” In other words, it’s often “too” correct. Additionally, ‘delve’ is considered much more commonplace in Nigeria:

INSIGHT: The Impact of Global Feedback on AI Performance
This actually accords with my own experience and explains something I’d encountered while beta testing for one of the AI-leading platforms (which shall remain nameless to protect the innocent).
I was testing a new model and found the output had strange idiosyncrasies, such as calling people “dear” in formal communications — not “Dear Mr X”, but inserting “dear” casually in sentences, such as “Thank you dear for your business inquiry”.
This usage, while endearing in some cultures, felt out of place in a Western professional context, illustrating how cultural nuances in language training can significantly influence how ‘natural-sounding’ an AI generator appears.
The reason this was occurring was that the new model had been fine-tuned based on customer feedback, and the writing platform catered to a South Asian market, where such terms reflect norms of formality and respect.
However, as the audience those users were using AI to address was English-speaking, the platform ultimately adjusted the imbalance in language style. This discrepancy illustrates how fine-tuning based on user feedback can lead to localized language preferences that may not universally resonate — nor actually be in the customers’ best interests of better communication.

The Benefits of Localized Language Preferences
While geographic and cultural skews in the training process can lead to an unintentional imprint on AI text generation, that’s not to say it’s inherently incorrect or necessarily problematic. Instead, it reflects the diverse ways English is used across different cultures and contexts. In fact, RLHF could help to mitigate controversial issues where AI exhibits Eurocentric biases due to underrepresentation in its training, allowing for a more inclusive approach (thereby making AI products better-suited for global outputs).
To return to our chef analogy, just as a skilled chef can learn to cater to different tastes, AI — guided by diverse RLHF — can flavor its outputs, so the final dish is palatable to a wider audience, or a culturally specific one.
🤝 Feel free to share a link to this article on your social media or LinkedIn.